To specify what data rows to retrieve from a Hadoop system running Hive, you write a query using HQL. As mentioned earlier, HQL is similar to SQL. HQL supports many of the same keywords as SQL, for example, SELECT, WHERE, GROUP BY, ORDER BY, JOIN, and UNION.
Hive transforms HQL statements into MapReduce jobs that Hadoop uses to perform and manage parallel processing across the clusters of servers. You can embed your own MapReduce scripts in the query by using the TRANSFORM clause. You make these scripts available to Hadoop through the Add File property when you configure the connection properties, as described in the previous section.
|
1
|
In Data Source Selection, select the Hive data source to use. Data Set Type displays HQL Select Query.
|
|
3
|
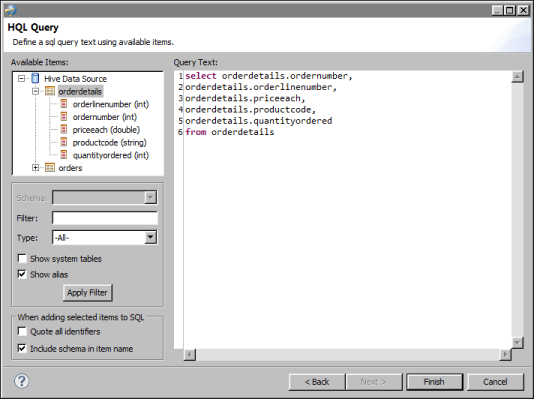
In HQL Query, in Query text, type a HQL statement that indicates what data to retrieve. Figure 10-2 shows an example of an HQL query specified in the data set editor.
|
|
Figure 10-2
|
|
4
|
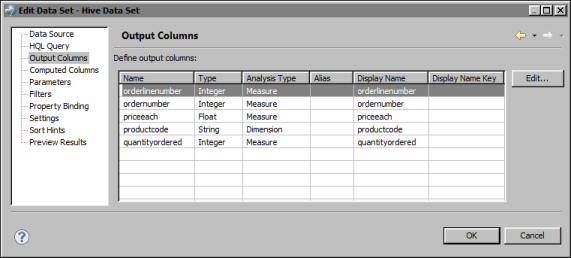
Choose Finish to save the data set. Edit Data Set displays the columns, and provides options for editing the data set, as shown in Figure 10-3.
|
|
Figure 10-3
|